원글 페이지 : 바로가기
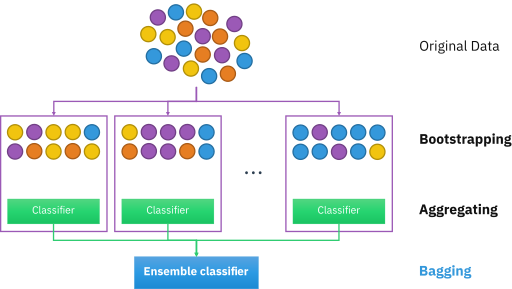
Ensemble(앙상블)이란? 여러개의 분류기를 생성하고 그 예측을 결합함으로써 최종 예측을 도출하는 방법 Bagging과 Boosting의 차이점 Bagging: 병렬적, parallel함 Bootstrap Aggregating, 부트스트랩(랜덤 샘플링)을 집계하는 것, 여러 샘플 조합에 대하여 하나의 알고리즘(모델) 활용 샘플링 과정은 복원추출임 데이터가 많지 않아도 충분한 학습효과를 주어 underfitting, overfitting 문제에 도움됨 Bagging의 대표적인 기법으로 RandomForest가 있음 https://data-analysis-science.tistory.com/61 Boosting: 순차적, sequential함 오분류된 학습 데이터에 대해서 가중치를 주고 다음 모델(분류기)에서 해당 데이터를 학습하게 유도 먼저 생성된 모델을 점점 발전시켜나가는 방법임 https://data-analysis-science.tistory.com/61 https://velog.io/@qqo222/%EB%B0%B0%EA%B9%85bagging Stacking: Cross validation 개별 모델이 예측한 결과를 다시 meta dataset으로 활용해서 학습함 Base learner 모델들의 validation, test dataset과 생성한 예측 값을 모아서 meta train/test 데이터로 활용함 하나의 데이터셋에 3개 이상의 알고리즘을 사용하여 예측 값을 만든다. 그리고 최종 모델의 학습 데이터로 사용한다. ex) KNN,Logistic, XGBoost, 모델을 사용해 3종류 예측 값을 구하고, 최종 모델인 RandomForest의 학습 데이터로 사용하여, 최종 예측값을 구함 https://www.researchgate.net/figure/Architecture-of-Voting-Regressor_fig2_371187155 출처1: https://lsjsj92.tistory.com/558 출처2: https://velog.io/@dltnstlssnr1/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-5%EB%8B%A8%EA%B3%84%EC%95%99%EC%83%81%EB%B8%94-%EB%B3%B4%ED%8C%85%EB%B0%B0%EA%B9%85%EB%B6%80%EC%8A%A4%ED%8C%85%EC%8A%A4%ED%83%9C%ED%82%B9 출처3: https://data-analysis-science.tistory.com/61 1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 안녕하세요, 허브솔트에요. 저희 데이터맛집의 허브솔트 첫 글 주제로 앙상블이 당첨됐네요…! 요새 캐글의 상위권 메달을 휩쓸고 있는 대세 알고리즘이 앙상블 기법을 사용한 알고리즘의 한 data-analysis-science.tistory.com 머신러닝-5단계(앙상블-보팅/배깅/부스팅/스태킹) 1) 앙상블은 여러 개의 모델을 결합하여 훨씬 강력한 모델을 생성하는 기법이다.2) 앙상블은 1. 보팅 2. 배깅 3. 부스팅 4. 스태킹 방법이 있다.3) 보팅(voting)은 하나의 데이터셋에 여러개의 알고리 velog.io 머신러닝 스태킹 앙상블(stacking ensemble) 이란? – 스태킹 앙상블 기본편(stacking ensemble basic) 포스팅 개요 머신러닝과 딥러닝에서 자주 사용하는 알고리즘이 있습니다. 특히, 머신러닝쪽에서 많이 사용하는데 그것은 앙상블(ensemble)이라는 방법입니다. 앙상블(ensemble)은 크게 보팅(voting), lsjsj92.tistory.com